

个人博客网站添加文章搜索功能
-
date_range 04/03/2019 06:06
点击量:次infosort网站label
现在很多网站页面里都有搜索模块,包括在线搜索、站内搜索等等,尤其是博客类网站,文章搜索功能就显得比较重要,现在以个人博客网站为例,详细介绍如何给页面添加搜索功能模块,至于如何搭建个人博客网站,可以参考这篇文章:https://andrewyghub.github.io/2018/04/01/github-pages-blog;
功能分析
为网页添加搜索模块的第三方网站有不少,实现效果也都不错,既然人家都能通过代码实现此功能,与其过度依赖第三方,何不自己研究一下原理自己实现呢_;
网页内搜索功能无非就是在文本输入框内输入一串想要搜索的关键字符串,点击搜索按钮后查找匹配出站内所有文章的匹配结果进行输出,再附上一个文章的链接;针对这个功能,作者本人第一时间想到的则是前端领域里的 Ajax,利用 XMLHttpRequest() 实现数据的交互,不清楚的可以自行百度快速补习,然后一般博客类网站都有 RSS 订阅功能及其数据页面,不清楚的也可以迅速百度了解一下,其实就是站内某个目录内存在一个叫 feed.xml 或者类似名字的页面,XML格式的,早期用于实现新闻内容订阅的,现在用的也比较广泛,里面存储的就是文章相关的一些数据,因此我们就可以获取这个文件里面的所有内容然后实现搜索匹配;
如果像我一样用 Gihub Pages 搭建的个人博客网站的话,无论用的 jekyll 或者 hexo,一般这个 feed.xml 文件就位于 根目录 下,并且该文件同时记录着某一篇文章所对应的 标题、页面链接、文章内容 等内容,这三个部分后面将用到,xml 内容大致如下:

当然有其他更好的实现方法可以自行参考或者在文末评论,那么接下来便通过这个方法来一步步实现搜素功能;
功能实现
先预览一下页面最终的实现效果:

或者在这里:https://andrewyghub.github.io/ 预览我的博客的搜索模块的最终实现;
HTML部分
即页面样式,组成很简单,即一个文本输入框<input>和一个搜索图标,这里图标可以自行搜索下载一个,或者像下面一样使用在线图标,全部代码如下:
先在<header></header>内部添加以下代码,使用在线图标:
<link href="https://fonts.googleapis.com/icon?family=Material+Icons"
rel="stylesheet">
然后在网页内需要添加搜索栏的合适位置添加以下代码,一般放在顶部导航栏:
<div class="search">
<i class="material-icons search-icon search-start">search</i>
<input type="text" class="search-input" placeholder="Searching..." />
<i class="material-icons search-icon search-clear">clear</i>
<div class="search-results"></div>
</div>
上面的clear是一个清除输入框内容的图标,search-results是用于输出匹配到的结果的板块;
CSS部分
然后来看一下CSS样式代码,仅供参考:
.search {
position: relative;
height: 30px;
text-align: right;
line-height: 30px;
padding-right: 10px;
}
.search .search-icon {
float: right;
height: 100%;
margin: 0 10px;
line-height: 30px;
cursor: pointer;
user-select: none;
}
.search .search-input {
float: right;
width: 30%;
height: 30px;
line-height: 30px;
margin: 0;
border: 2px solid #ddd;
border-radius: 10px;
box-sizing: border-box;
}
.search .search-clear {
display: none;
}
.search .search-results {
display: block;
z-index: 1000;
position: absolute;
top: 30px;
right: 50px;
width: 50%;
max-height: 400px;
overflow: auto;
text-align: left;
border-radius: 5px;
background: #ccc;
box-shadow: 0 .3rem .5rem #333;
}
.search .search-results .result-item {
background: aqua;
color: #000;
margin: 5px;
padding: 3px;
border-radius: 3px;
cursor: pointer;
}
样式可以自行随意调整,最终感觉好看就OK;
JavaScript部分
接下来就是重头戏了,也是实现搜索功能的核心部分,搜索逻辑的实现;
再来大致分析一下逻辑,和实现的思路:
- 利用XMLHttpRequest()获取站内feed.xml内的所有数据,保存到一个XML DOM对象中;
- 将XML对象中的文章标题、链接、内容、索引等通过
getElementsByTagName()等方法获取并保存到对应数组变量中; - 用户在输入框输入查找内容,提交后内容保存到一个字符串类型变量中;
- 遍历保存文章内容的数组,通过
.search()等方法和输入值进行匹配; - 匹配成功后得到所有匹配成功的数组元素的索引值,该索引值也是该内容的标题、链接数组对应的索引值;
- 将最终搜集的文章标题、链接,以及匹配到的内容片段摘取输出到页面;
这里附上最终的 js 实现代码与注释:
// 获取搜索框、搜索按钮、清空搜索、结果输出对应的元素
var searchBtn = document.querySelector('.search-start');
var searchClear = document.querySelector('.search-clear');
var searchInput = document.querySelector('.search-input');
var searchResults = document.querySelector('.search-results');
// 申明保存文章的标题、链接、内容的数组变量
var searchValue = '',
arrItems = [],
arrContents = [],
arrLinks = [],
arrTitles = [],
arrResults = [],
indexItem = [],
itemLength = 0;
var tmpDiv = document.createElement('div');
tmpDiv.className = 'result-item';
// ajax 的兼容写法
var xhr = new XMLHttpRequest() || new ActiveXObject('Microsoft.XMLHTTP');
xhr.onreadystatechange = function () {
if (xhr.readyState == 4 && xhr.status == 200) {
xml = xhr.responseXML;
arrItems = xml.getElementsByTagName('item');
itemLength = arrItems.length;
// 遍历并保存所有文章对应的标题、链接、内容到对应的数组中
// 同时过滤掉 HTML 标签
for (i = 0; i < itemLength; i++) {
arrContents[i] = arrItems[i].getElementsByTagName('description')[0].
childNodes[0].nodeValue.replace(/<.*?>/g, '');
arrLinks[i] = arrItems[i].getElementsByTagName('link')[0].
childNodes[0].nodeValue.replace(/<.*?>/g, '');
arrTitles[i] = arrItems[i].getElementsByTagName('title')[0].
childNodes[0].nodeValue.replace(/<.*?>/g, '');
}
}
}
// 开始获取根目录下 feed.xml 文件内的数据
xhr.open('get', '/feed.xml', true);
xhr.send();
searchBtn.onclick = searchConfirm;
// 清空按钮点击函数
searchClear.onclick = function(){
searchInput.value = '';
searchResults.style.display = 'none';
searchClear.style.display = 'none';
}
// 输入框内容变化后就开始匹配,可以不用点按钮
// 经测试,onkeydown, onchange 等方法效果不太理想,
// 存在输入延迟等问题,最后发现触发 input 事件最理想,
// 并且可以处理中文输入法拼写的变化
searchInput.oninput = function () {
setTimeout(searchConfirm, 0);
}
searchInput.onfocus = function () {
searchResults.style.display = 'block';
}
function searchConfirm() {
if (searchInput.value == '') {
searchResults.style.display = 'none';
searchClear.style.display = 'none';
} else if (searchInput.value.search(/^\s+$/) >= 0) {
// 检测输入值全是空白的情况
searchInit();
var itemDiv = tmpDiv.cloneNode(true);
itemDiv.innerText = '请输入有效内容...';
searchResults.appendChild(itemDiv);
} else {
// 合法输入值的情况
searchInit();
searchValue = searchInput.value;
// 在标题、内容中查找
searchMatching(arrTitles, arrContents, searchValue);
}
}
// 每次搜索完成后的初始化
function searchInit() {
arrResults = [];
indexItem = [];
searchResults.innerHTML = '';
searchResults.style.display = 'block';
searchClear.style.display = 'block';
}
function searchMatching(arr1, arr2, input) {
// 忽略输入大小写
input = new RegExp(input, 'i');
// 在所有文章标题、内容中匹配查询值
for (i = 0; i < itemLength; i++) {
if (arr1[i].search(input) !== -1 || arr2[i].search(input) !== -1) {
// 优先搜索标题
if (arr1[i].search(input) !== -1) {
var arr = arr1;
} else {
var arr = arr2;
}
indexItem.push(i); // 保存匹配值的索引
var indexContent = arr[i].search(input);
// 此时 input 为 RegExp 格式 /input/i,转换为原 input 字符串长度
var l = input.toString().length - 3;
var step = 10;
// 将匹配到内容的地方进行黄色标记,并包括周围一定数量的文本
arrResults.push(arr[i].slice(indexContent - step, indexContent) +
'<mark>' + arr[i].slice(indexContent, indexContent + l) + '</mark>' +
arr[i].slice(indexContent + l, indexContent + l + step));
}
}
// 输出总共匹配到的数目
var totalDiv = tmpDiv.cloneNode(true);
totalDiv.innerHTML = '总匹配:<b>' + indexItem.length + '</b> 项';
searchResults.appendChild(totalDiv);
// 未匹配到内容的情况
if (indexItem.length == 0) {
var itemDiv = tmpDiv.cloneNode(true);
itemDiv.innerText = '未匹配到内容...';
searchResults.appendChild(itemDiv);
}
// 将所有匹配内容进行组合
for (i = 0; i < arrResults.length; i++) {
var itemDiv = tmpDiv.cloneNode(true);
itemDiv.innerHTML = '<b>《' + arrTitles[indexItem[i]] +
'》</b><hr />' + arrResults[i];
itemDiv.setAttribute('onclick', 'changeHref(arrLinks[indexItem[' + i + ']])');
searchResults.appendChild(itemDiv);
}
}
function changeHref(href) {
// 在当前页面点开链接的情况
location.href = href;
// 在新标签页面打开链接的代码,与上面二者只能取一个,自行决定
// window.open(href);
}
可以把上面的代码保存到search-box.js这样的 js 文件中,然后引入到 html 页面里;
看一下最终效果:
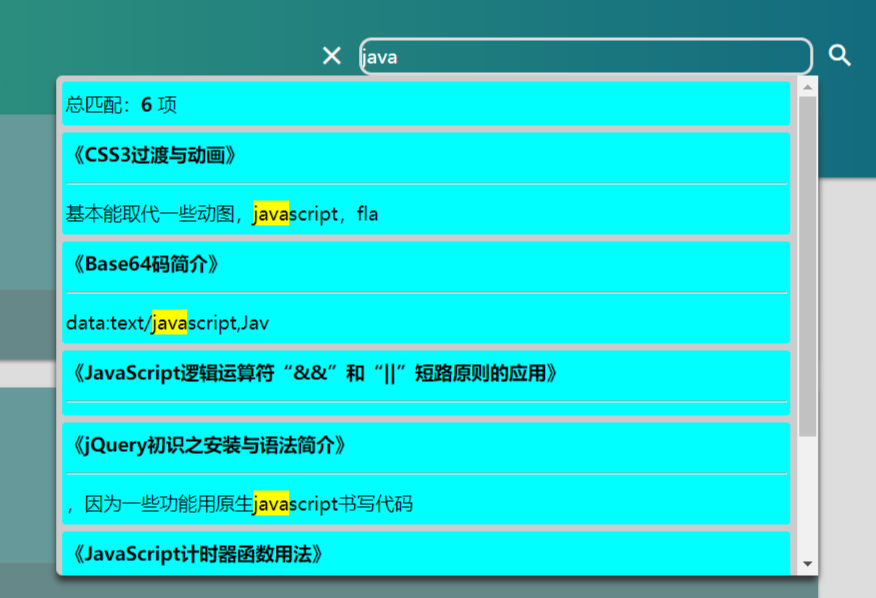
或者来我的主页查看:https://andrewyghub.github.io/
评论:
技术文章推送
手机、电脑实用软件分享

 微信公众号:AndrewYG的算法世界
微信公众号:AndrewYG的算法世界