

数据库-Redis
-
date_range 05/06/2019 18:38
点击量:次infosort面试label
数据类型
来源:https://redisbook.readthedocs.io/en/latest/internal/db.html#id4
Redis是一个键值对数据库,数据库中的键值对由字典保存。每个数据库都有一个对应的字典,这个字典被称之为键空间。当用户添加一个键值对到数据库时(不论键值对是什么类型), 程序就将该键值对添加到键空间
字典的键是一个字符串对象。字典的值则可以是包括【字符串、列表、哈希表、集合或有序集】在内的任意一种 Redis 类型对象。
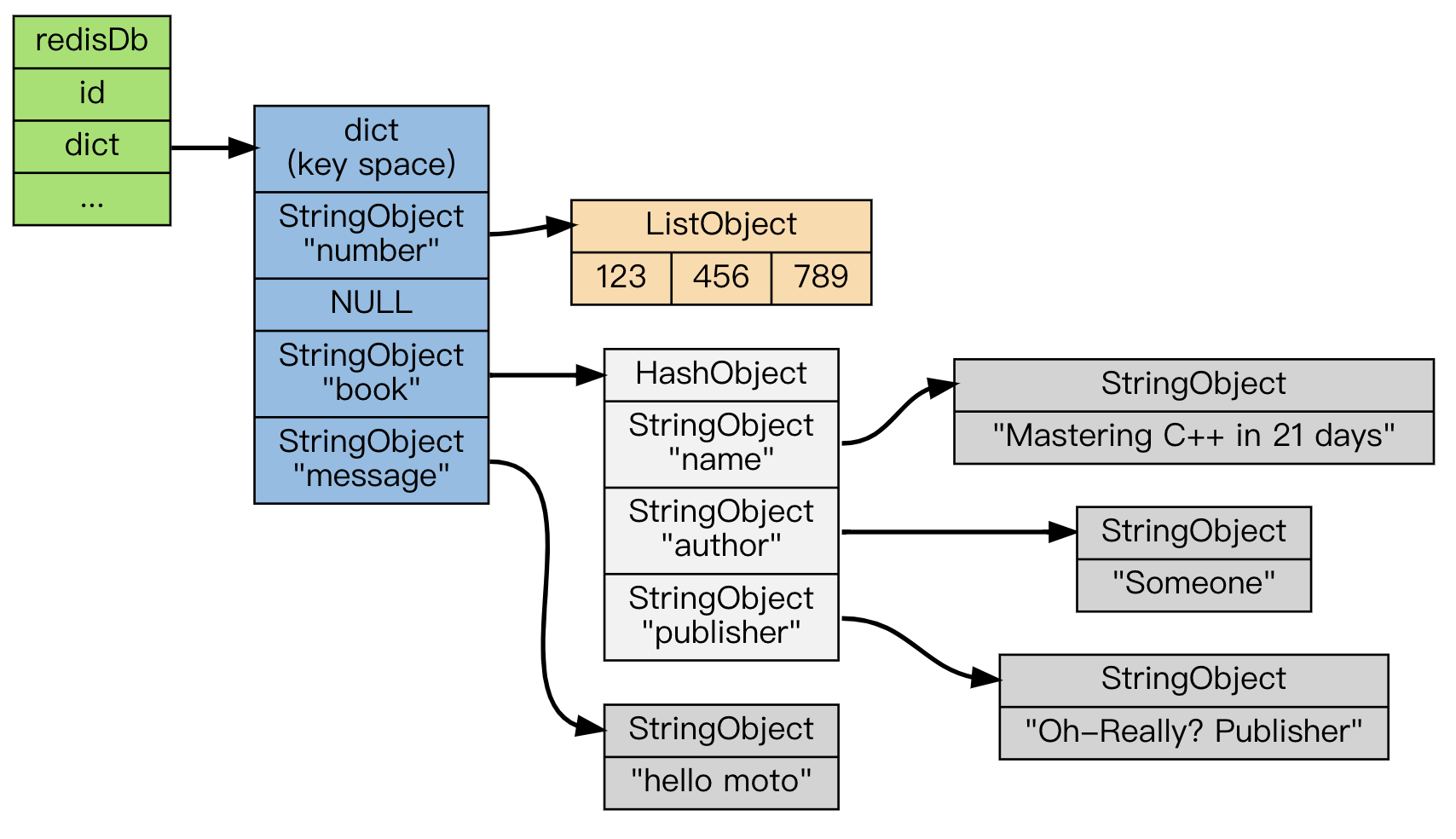
上图展示了一个包含 number 、 book 、 message 三个键的数据库 —— 其中 number 键是一个列表,列表中包含三个整数值; book 键是一个哈希表,表中包含三个键值对; 而 message 键则指向另一个字符串:
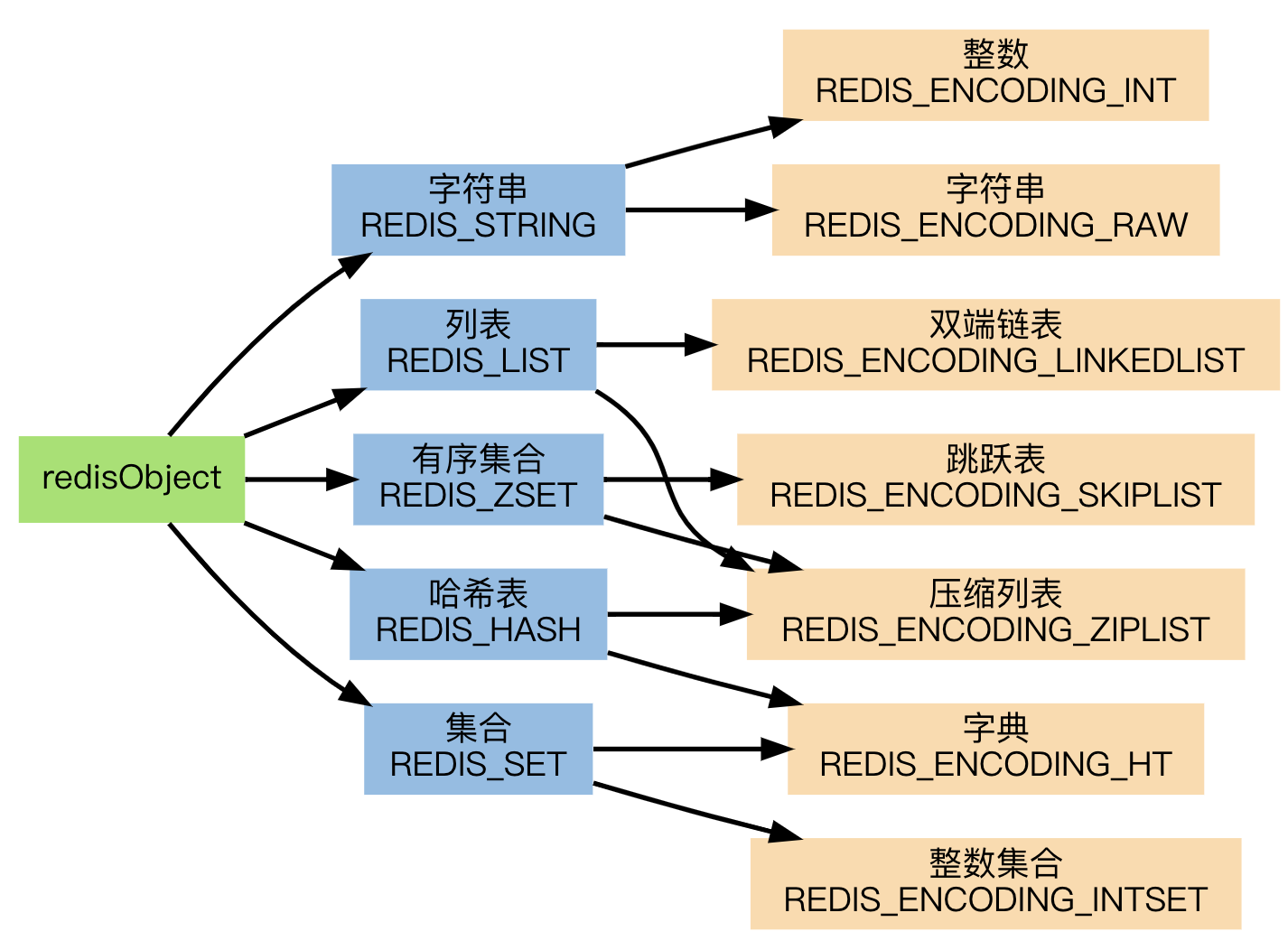
不同的数据类型的具体实现(压缩列表、跳表必看)请看: https://redisbook.readthedocs.io/en/latest/index.html#id3
在线文档:http://118.25.23.115/
压缩链表原理: 在内存中是连续存储的,但是不同于数组,为了节省内存,ziplist的每个元素所占的内存大小可以不同 ziplist将一些必要的偏移量信息记录在了每一个节点里,使之能跳到上一个节点或下一个节点
与跳表应用场景: 当zset满足以下两个条件的时候,使用ziplist:
- 保存的元素少于128个
- 保存的所有元素大小都小于64字节
redis数据过期策略: 定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除 惰性过期:只有当访问一个key时,才会判断该key是否已过期,过期则清除 定期过期:每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key
内存淘汰策略: no-eviction:当内存不足以容纳新写入数据时,新写入操作会报错 allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除
集群模式
来源:
https://my.oschina.net/zhangxufeng/blog/905611
https://www.cnblogs.com/leeSmall/p/8398401.html
https://docs.aws.amazon.com/zh_cn/AmazonElastiCache/latest/red-ug/CacheNodes.NodeGroups.html
主从
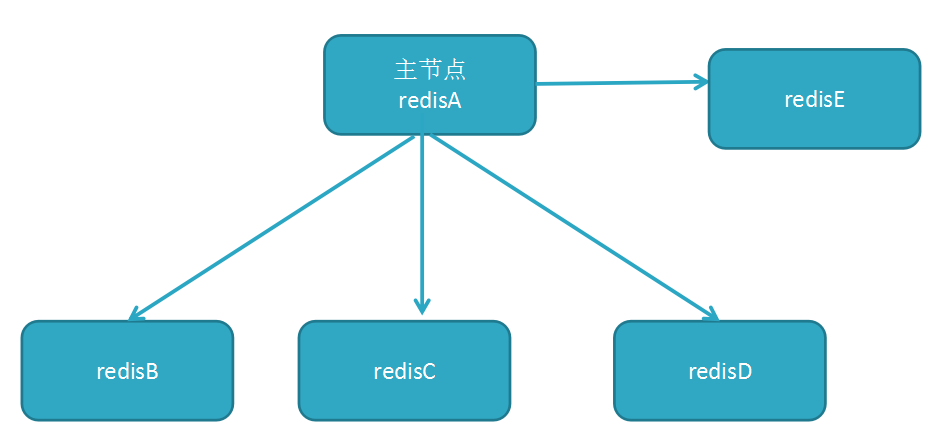
用一个redis实例作为主机,其余的实例作为从机。主机和从机的数据完全一致,主机支持数据的写入和读取等各项操作,而从机则只支持与主机数据的同步和读取。因而可以将写入数据的命令发送给主机执行,而读取数据的命令发送给不同的从机执行,从而达到读写分离的目的。
问题是主从模式如果所连接的redis实例因为故障下线了,没有提供一定的手段通知客户端另外可连接的客户端地址,因而需要手动更改客户端配置重新连接。如果主节点由于故障下线了,那么从节点因为没有主节点而同步中断,因而需要人工进行故障转移工作。为了解决这两个问题,在2.8版本之后redis正式提供了sentinel(哨兵)架构。
哨兵
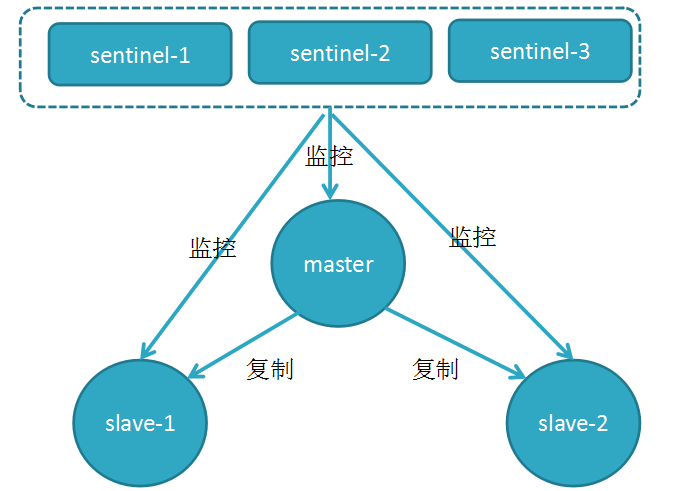
由Sentinel节点定期监控发现主节点是否出现了故障,当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。
集群
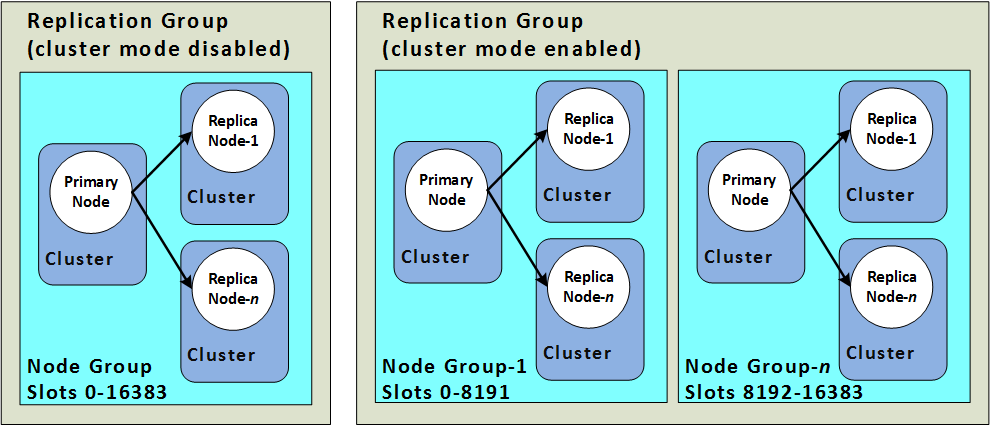
redis主从或哨兵模式的每个实例都是全量存储所有数据,浪费内存且有木桶效应。为了最大化利用内存,可以采用集群,就是分布式存储。集群将数据分片存储,每组节点存储一部分数据,从而达到分布式集群的目的。
上图是主从模式与集群模式的区别,redis集群中数据是和槽(slot)挂钩的,其总共定义了16384个槽,所有的数据根据一致哈希算法会被映射到这16384个槽中的某个槽中;另一方面,这16384个槽是按照设置被分配到不同的redis节点上。
但集群模式会直接导致访问数据方式的改变,比如客户端向A节点发送GET命令但该数据在B节点,redis会返回重定向错误给客户端让客户端再次发送请求,这也直接导致了必须在相同节点才能执行的一些高级功能(如Lua、事务、Pipeline)无法使用。另外还会引发数据分配的一致性hash问题可以参看这里
如何选择
- 集群的优势在于高可用,将写操作分开到不同的节点,如果写的操作较多且数据量巨大,且不需要高级功能则可能考虑集群
- 哨兵的优势在于高可用,支持高级功能,且能在读的操作较多的场景下工作,所以在绝大多数场景中是适合的
- 主从的优势在于支持高级功能,且能在读的操作较多的场景下工作,但无法保证高可用,不建议在数据要求严格的场景下使用
使用策略
延迟加载
读:当读请求到来时,先从缓存读,如果读不到就从数据库读,读完之后同步到缓存且添加过期时间
写:当写请求到来时,只写数据库
优点:仅对请求的数据进行一段时间的缓存,没有请求过的数据就不会被缓存,节省缓存空间;节点出现故障并不是致命的,因为可以从数据库中得到
缺点:缓存数据不是最新的;【缓存击穿】;【缓存失效】
直写
读:当读请求到来时,先从缓存读,如果读不到就从数据库读,读完之后同步到缓存且设置为永不过期
写:当写请求到来时,先写数据库然后同步到缓存,设置为永不过期
优点:缓存数据是最新的,无需担心缓存击穿、失效问题,编码方便
缺点:大量数据可能没有被读取的资源浪费;节点故障或重启会导致缓存数据的丢失直到有写操作同步到缓存;每次写入都需要写缓存导致的性能损失
永不过期的缓存会大量占用空间,可以设置过期时间来改进,但是会引进【缓存失效】问题,需要注意解决
如何选择
如果需要缓存与数据库数据保持实时一致,则需要选择直写方式
如果缓存服务很稳定、缓存的可用空间大、写缓存的性能丢失能够接受,选择直写方式比较方便实现
否则选择延迟加载,同时注意解决引进的问题
缓存问题
缓存击穿
查询一个数据库中不存在的数据,比如商品详情,查询一个不存在的ID,每次都会访问DB,如果有人恶意破坏,很可能直接对DB造成过大地压力。
当通过某一个key去查询数据的时候,如果对应在数据库中的数据都不存在,我们将此key对应的value设置为一个默认的值。
缓存失效
在高并发的环境下,如果此时key对应的缓存失效,此时有多个进程就会去同时去查询DB,然后再去同时设置缓存。这个时候如果这个key是系统中的热点key或者同时失效的数量比较多时,DB访问量会瞬间增大,造成过大的压力。
将系统中key的缓存失效时间均匀地错开
热点key
缓存中的某些Key(可能对应用与某个促销商品)对应的value存储在集群中一台机器,使得所有流量涌向同一机器,成为系统的瓶颈,该问题的挑战在于它无法通过增加机器容量来解决。
- 客户端热点key缓存:将热点key对应value并缓存在客户端本地,并且设置一个失效时间。
- 将热点key分散为多个子key,然后存储到缓存集群的不同机器上,这些子key对应的value都和热点key是一样的。
持久化
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。 AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。 Redis 还可以在后台对 AOF 文件进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。
Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。
但实际上持久化会对Redis的性能造成非常严重的影响,如果一定需要保存数据,那么数据就不应该依靠缓存来保存,建议使用其他方式如数据库。所以Redis的持久化意义不大。
评论:
技术文章推送
手机、电脑实用软件分享

 微信公众号:AndrewYG的算法世界
微信公众号:AndrewYG的算法世界