

分布式-一致性hash
-
date_range 12/06/2019 21:41
点击量:次infosort面试label
一致 Hash 算法
分布式缓存中,如何将数据均匀的分散到各个节点中,并且尽量的在加减节点时能使受影响的数据最少。
Hash 取模
随机放置就不说了,会带来很多问题。通常最容易想到的方案就是 hash 取模了。
可以将传入的 Key 按照 index = hash(key) % N 这样来计算出需要存放的节点。其中 hash 函数是一个将字符串转换为正整数的哈希映射方法,N 就是节点的数量。
这样可以满足数据的均匀分配,但是这个算法的容错性和扩展性都较差。
比如增加或删除了一个节点时,所有的 Key 都需要重新计算,显然这样成本较高,为此需要一个算法满足分布均匀同时也要有良好的容错性和拓展性。
一致 Hash 算法
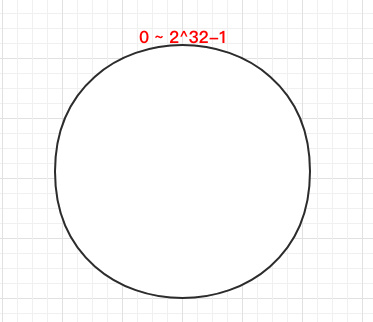
一致 Hash 算法是将所有的哈希值构成了一个环,其范围在 0 ~ 2^32-1。如下图:
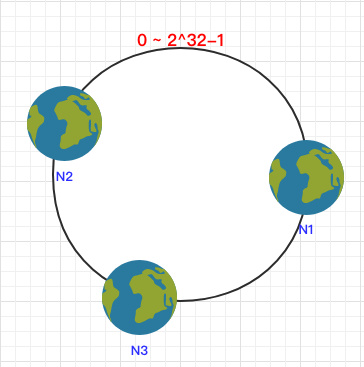
之后将各个节点散列到这个环上,可以用节点的 IP、hostname 这样的唯一性字段作为 Key 进行 hash(key),散列之后如下:
之后需要将数据定位到对应的节点上,使用同样的 hash 函数 将 Key 也映射到这个环上。
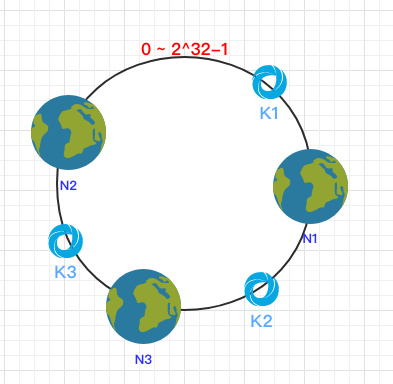
这样按照顺时针方向就可以把 k1 定位到 N1节点,k2 定位到 N3节点,k3 定位到 N2节点。
容错性
这时假设 N1 宕机了:
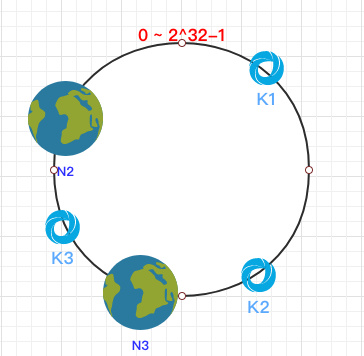
依然根据顺时针方向,k2 和 k3 保持不变,只有 k1 被重新映射到了 N3。这样就很好的保证了容错性,当一个节点宕机时只会影响到少少部分的数据。
拓展性
当新增一个节点时:
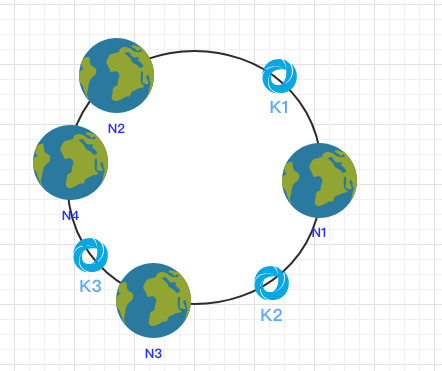
在 N2 和 N3 之间新增了一个节点 N4 ,这时会发现受影响的数据只有 k3,其余数据也是保持不变,所以这样也很好的保证了拓展性。
虚拟节点
到目前为止该算法依然也有点问题:
当节点较少时会出现数据分布不均匀的情况:
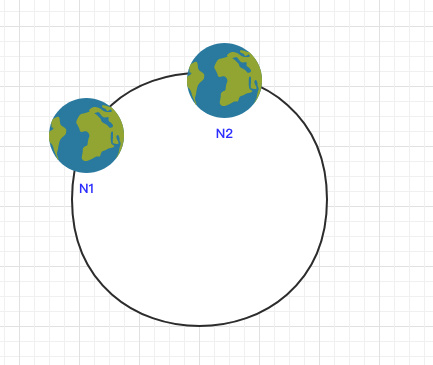
这样会导致大部分数据都在 N1 节点,只有少量的数据在 N2 节点。
为了解决这个问题,一致哈希算法引入了虚拟节点。将每一个节点都进行多次 hash,生成多个节点放置在环上称为虚拟节点:
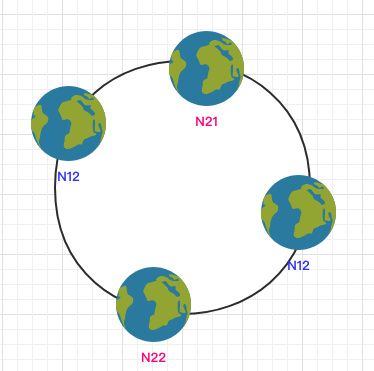
计算时可以在 IP 后加上编号来生成哈希值。
这样只需要在原有的基础上多一步由虚拟节点映射到实际节点的步骤即可让少量节点也能满足均匀性。
https://github.com/crossoverJie/JCSprout/blob/master/MD/Consistent-Hash.md
Redis用了吗?
降低扩容缩容时传统哈希算法重建映射影响范围,一致性哈希不是唯一的解决办法。
redis 缓存采用了固定哈希槽的方式维护 Key 和存储节点的关系。每个节点负责一部分槽,槽的总数是固定的 16384,无论节点数怎么变, Key 进行哈希运算再对槽总数取模的值都是不变的。
插入数据时,先算出数据应该分配到哪个槽,再去查槽在哪个节点,这样就实现了把 Key 通过哈希算法均匀的分布到大量的槽上。槽分配到哪个节点是人为配置的,只要配置的槽均匀,最终节点上的 Key 就会均匀分布到物理节点,扩容缩容时也只需要迁移部分槽的数据。
在一致性哈希算法中,引入虚拟节点其实和固定哈希槽有异曲同工之妙,都是将最终存储的节点和数据的 Key 之间多做一层转换,避免节点总数的变动影响太多映射关系,虽然固定哈希槽不如一致性哈希加虚拟节点灵活,但是考虑到 redis 的存储的数据量级与多数分布式数据库相比差距很大, 固定哈希槽策略对于 redis 已经完全够用了。
一致性哈希算法的应用非常广泛,在分布式数据库 Cassandra 、缓存Memcache、分布式服务框架Dubbo中都有应用。
评论:
技术文章推送
手机、电脑实用软件分享

 微信公众号:AndrewYG的算法世界
微信公众号:AndrewYG的算法世界